2020年10月30日
大数据随记2
简单了解了一下spark的一些东西
RDD,一种计算模型,有一系列的特征,不存储数据,只是添加运算的逻辑,分组汇总,格式转化等等,每添加一段逻辑,就要生成新的RDD,最终cellect()的时候在执行。
累加器,可以自定义累加的逻辑,最终结果返回到driver层,可以在一些情况下优化rdd的效率
广播变量,全局只读的一个东西,也是可以优化效率,防止多次重复读取数据
也可以用thredLocal来做一些优化,比如全局的spark环境变量等
sparkSql,写法类似sql,也有一些特殊的东西,可以代码中指定临时表,可以自定义聚合函数等,兼容hive,好像是从hive演变过来的,hive不熟,先不管。
sparkSql的使用,就用sql的形式,完成了一些rdd的操作,比较方便快捷。


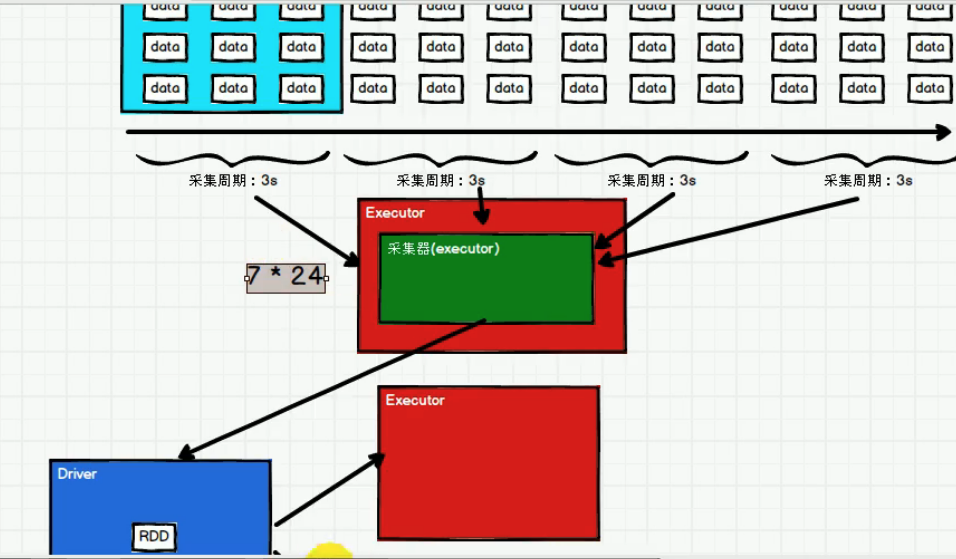
采集器实际上是在exccutor中运行的

由于要启动driver和采集器,最少需要两个线程local[2]
实际项目中,一般flume采集数据到kafka,kafka对接sparkStreaming。