io线程模型
(26条消息) IO线程模型知识_LonglyDean的博客-CSDN博客_io线程
这篇讲的不错,直接收藏了。
存在问题:
- 当并发数很大,就会创建大量的线程,占用很大系统资源
- 连接创建后,如果当前线程暂时没有数据可读,该线程会阻塞在 read 操作,造成线程资源浪费
Reactor 模型
Reactor 模式,通过一个或多个输入同时传递给服务处理器的模式 , 服务器端程序处理传入的多个请求,并将它们同步分派到相应的处理线程, 因此 Reactor 模式也叫 Dispatcher模式. Reactor 模式使用IO 复用监听事件, 收到事件后,分发给某个线程(进程), 这点就是网络服务器高并发处理关键.
- 单 Reactor 单线程
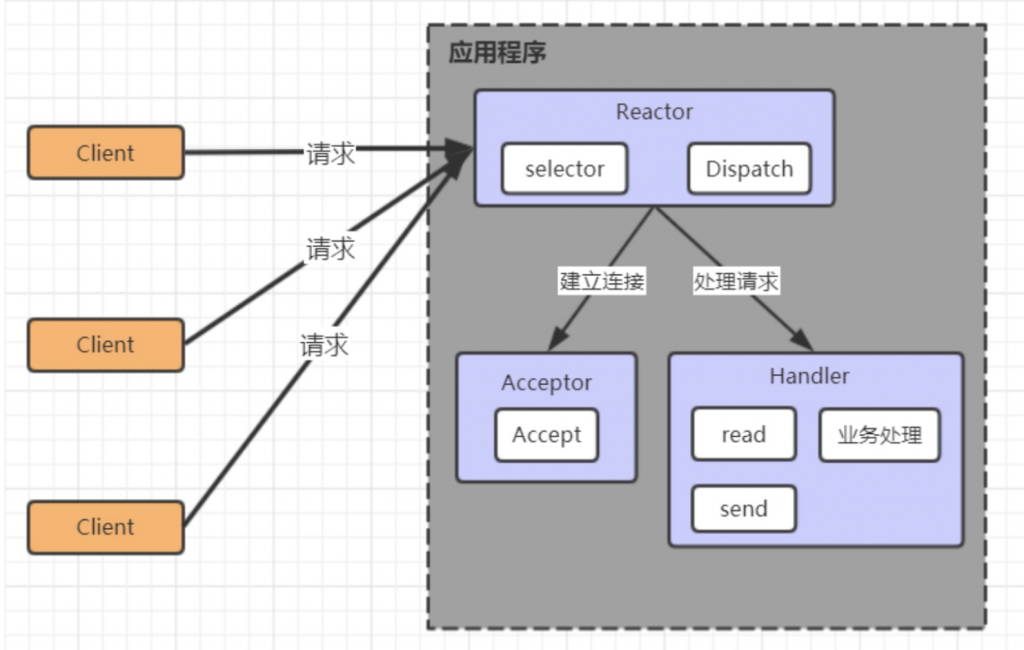
Selector是可以实现应用程序通过一个阻塞对象监听多路连接请求
Reactor 对象通过 Selector监控客户端请求事件,收到事件后通过 Dispatch 进行分发
是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后的后续业务处理
Handler 会完成 Read→业务处理→Send 的完整业务流程
优点:
模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成
缺点:
1. 性能问题: 只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈
2. 可靠性问题: 线程意外终止或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障
- 单 Reactor多线程
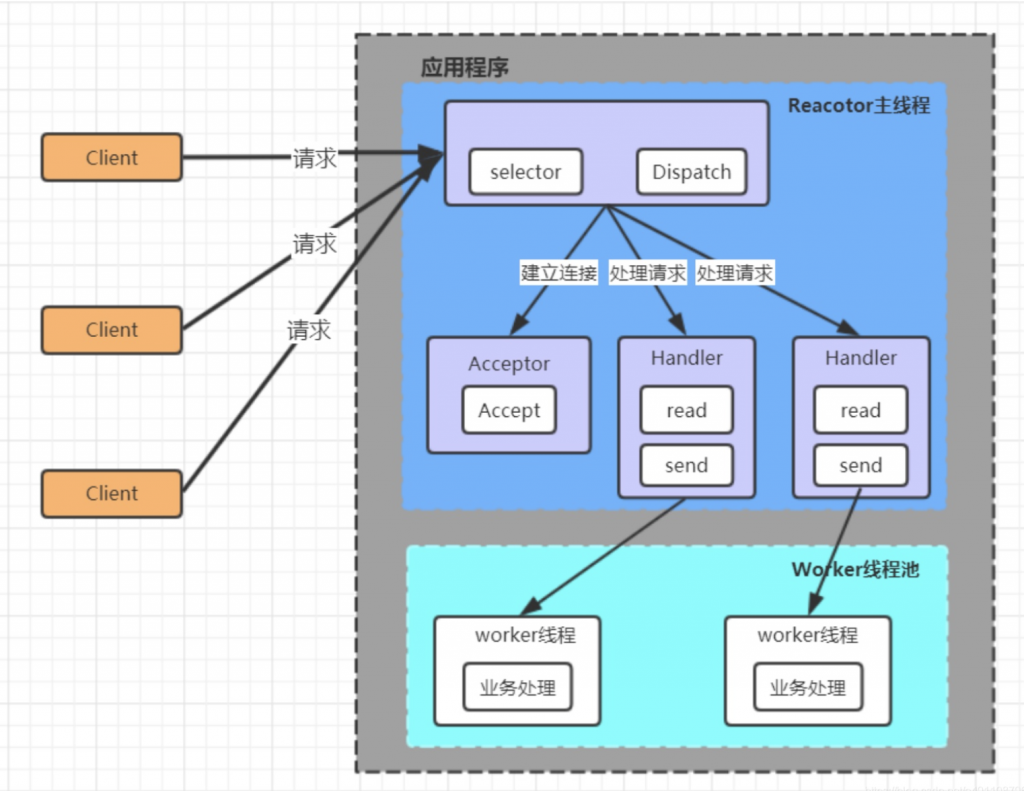
Reactor 对象通过 selector 监控客户端请求事件, 收到事件后,通过 dispatch 进行分发
如果建立连接请求, 则右 Acceptor 通过accept 处理连接请求
如果不是连接请求,则由 reactor 分发调用连接对应的 handler 来处理
handler 只负责响应事件,不做具体的业务处理, 通过 read 读取数据后,会分发给后面的worker 线程池的某个线程处理业务
worker 线程池会分配独立线程完成真正的业务,并将结果返回给 handler
handler 收到响应后,通过 send 将结果返回给 client
优点:
可以充分的利用多核 cpu 的处理能力
缺点:
多线程数据共享和访问比较复杂, reactor 处理所有的事件的监听和响应,在单线程运行, 在
高并发场景容易出现性能瓶颈
- 主从 Reactor 多线程
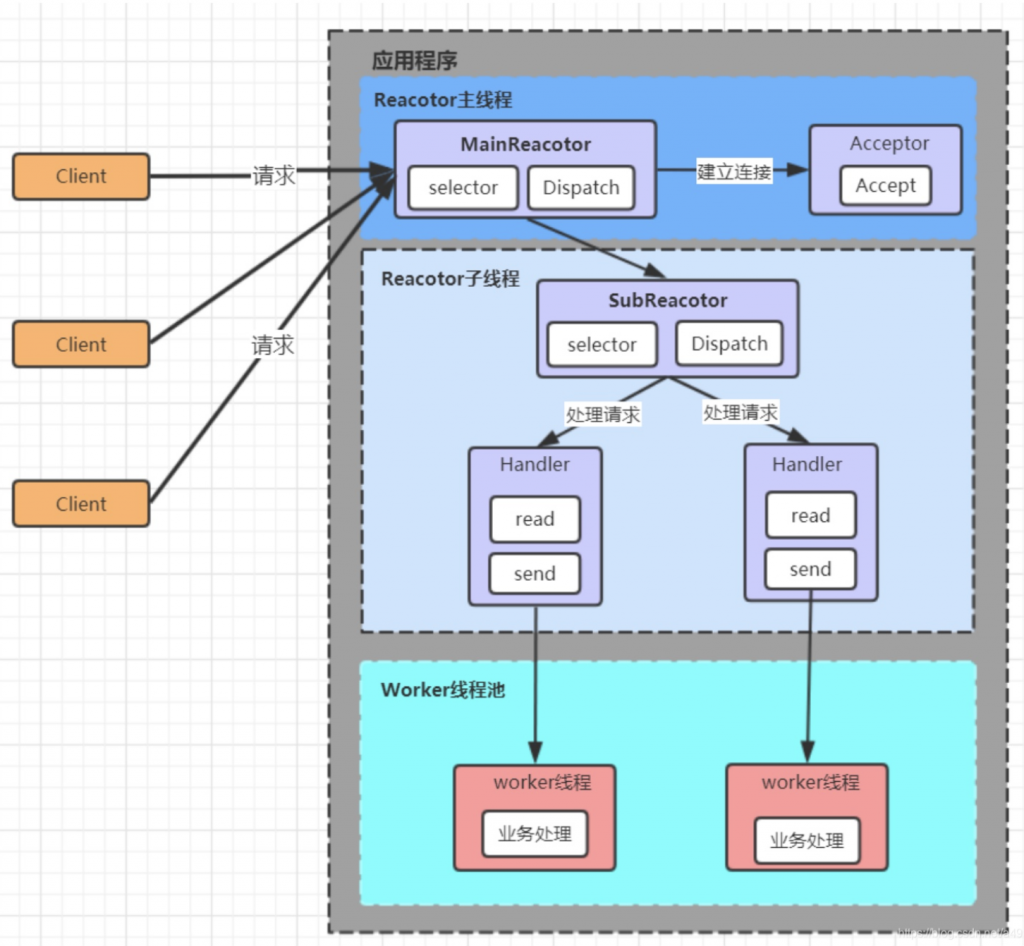
Reactor 主线程 MainReactor 对象通过 select 监听客户端连接事件,收到事件后,通过Acceptor 处理客户端连接事件
当 Acceptor 处理完客户端连接事件之后(与客户端建立好 Socket 连接),MainReactor 将连接分配给 SubReactor。(即:MainReactor 只负责监听客户端连接请求,和客户端建立连接之后将连接交由 SubReactor 监听后面的 IO 事件。)
SubReactor 将连接加入到自己的连接队列进行监听,并创建 Handler 对各种事件进行处理
当连接上有新事件发生的时候,SubReactor 就会调用对应的 Handler 处理
Handler 通过 read 从连接上读取请求数据,将请求数据分发给 Worker 线程池进行业务处理
Worker 线程池会分配独立线程来完成真正的业务处理,并将处理结果返回给 Handler。Handler 通过 send 向客户端发送响应数据
一个 MainReactor 可以对应多个 SubReactor,即一个 MainReactor 线程可以对应多个SubReactor 线程
优点:
1. MainReactor 线程与 SubReactor 线程的数据交互简单职责明确,MainReactor 线程只需要接收新连接,SubReactor 线程完成后续的业务处理
2. MainReactor 线程与 SubReactor 线程的数据交互简单, MainReactor 线程只需要把新连接传给 SubReactor 线程,SubReactor 线程无需返回数据
3. 多个 SubReactor 线程能够应对更高的并发请求
缺点:
这种模式的缺点是编程复杂度较高。但是由于其优点明显,在许多项目中被广泛使用,包括
Nginx、Memcached、Netty 等。这种模式也被叫做服务器的 1+M+N 线程模式,即使用该模式开发的服务器包含一个(或多个,1 只是表示相对较少)连接建立线程+M 个 IO 线程+N 个业务处理线程。这是业界成熟的服务器程序设计模式。
Netty的IO模型
介绍完网络数据包在内核中的收发过程以及五种IO模型和两种线程模型后,线程我们来看下Netty中的IO模型是什么样的。
在我们介绍Reactor IO线程模型的时候提到有三种Reactor模型:单Reactor单线程,单Reactor多线程,主从Reactor多线程。
这三种Reactor模型在netty中都是支持的,但是我们常用的是主从Reactor多线程模型。
而我们之前介绍的三种Reactor只是一种模型,是一种设计思想。实际上各种网络框架在实现中并不是严格按照模型来实现的,会有一些小的不同,但大体设计思想上是一样的。
下面我们来看下netty中的主从Reactor多线程模型是什么样子:
- Reactor在netty中是以group的形式出现的。netty中将Reactor分为两组,一组是MainReactorGroup也就是我们在编码中常常看到的EventLoopGroup bossGroup,另一组是SubReactorGroup也就是我们在编码中常常看到的EventLoopGroup workerGroup。
- MainReactorGroup通常只有一个Reactor,专门负责做重要的事情,也就是监听连接accept事件。当有连接事件产生时,在对应的处理handler acceptor中创建初始化相应的NioSocketChannel(代表一个Socket连接)。然后以负载均衡的方式在SubReactorGroup中选取一个Reactor,注册上去,监听Read事件。
MainReactorGroup中只有一个Reactor的原因是,通常我们的服务端程序只会绑定监听一个端口,如果绑定监听多个端口,就会配置多个Reactor。
- SubReactorGroup中有多个Reactor,具体Reactor的个数可以由系统参数 -D io.netty.evnetLoopThreads指定。默认的Reactor的个数为CPU核数*2。SubReactorGroup中的Reactor主要负责监听读写事件,每个Reactor负责监听一组socket连接。将全部的连接分摊在多个Reactor中。
- 一个Reactor分配一个IO线程,这个IO线程负责从Reactor中获取IO就绪事件,执行IO调用获取IO数据,执行PipeLine。
socket连接在创建后就被固定的分配给一个Reactor,所以一个socket连接也只会被一个固定的IO线程执行,每个socket连接分配一个独立的PipeLine实例,用来编排这个socket连接上的IO处理逻辑。这种无锁串行化的设计目的是为了防止线程并发执行同一个socket连接上的IO逻辑处理,防止出现线程安全问题。同时使系统吞吐量达到最大化
由于每个Reactor中只有一个IO线程,这个IO线程叫执行IO活跃的socket连接对应的Pipeline中的ChannelHandler,又要从Reactor中获取IO就绪事件,执行IO调用。所以Pipeline中channelhandler中执行的逻辑不能耗时太长,尽量将耗时的业务逻辑处理放入单独的业务线程池中处理,否则会影响其它连接的IO读写,从而近一步影响到整个服务程序的IO吞吐。
当IO请求在业务线程中完成相应的业务逻辑处理后,在业务线程中利用持有的ChannelHandlerContext引用将响应数据在Pipeline中反向传播,最终写回给客户端。
netty支持的三种Reactor模型:
配置单Reactor单线程
EventLoopGroup eventGroup = new NioEventLoopGroup(1); ServerBootstrap serverBootstrap = new ServerBootstrap(); serverBootstrap.group(eventGroup);
配置单Reactor多线程
EventLoopGroup eventGroup = new NioEventLoopGroup(); ServerBootstrap serverBootstrap = new ServerBootstrap(); serverBootstrap.group(eventGroup);
配置主从Reactor多线程
EventLoopGroup bossGroup = new NioEventLoopGroup(1); EventLoopGroup workerGroup = new NioEventLoopGroup(); ServerBootstrap serverBootstrap = new ServerBootstrap(); serverBootstrap.group(bossGroup, workerGroup);